Large Margin Classification
So we have seen many supervised algorithms till now.It does not matter which supervised algorithm we are using, the thing matter is the how much data we are going to use and our skill in applying these algorithms.
Support vector machine is also one of the type of algorithm which is very widely used in today’s world.Support vector machine gives us a more powerful way of learning complex non-linear functions then linear regression and neural networks.
So we can write mathematical definition for svm for our logistic regression as following
[Note:derivation is out of scope]
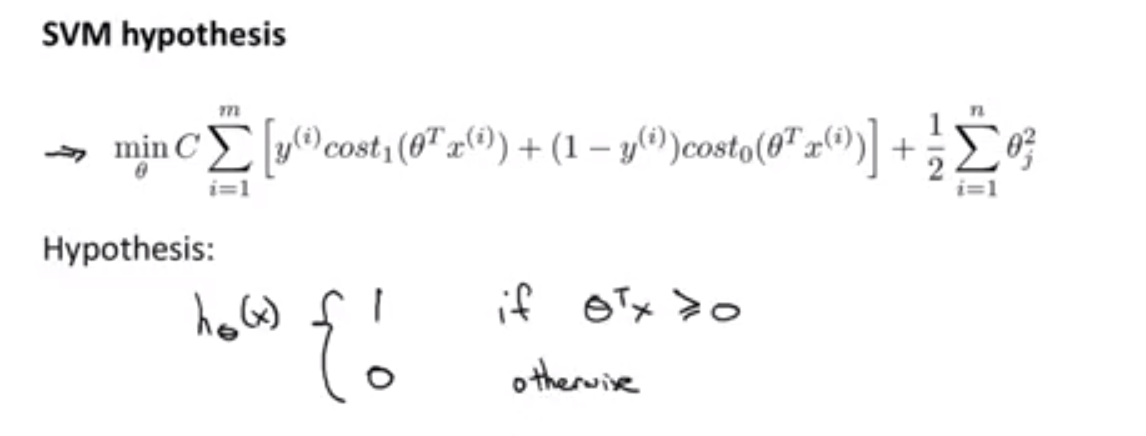
Large Margin Intuition
So we will have following cost functions and respective graph in support vector machine as following:

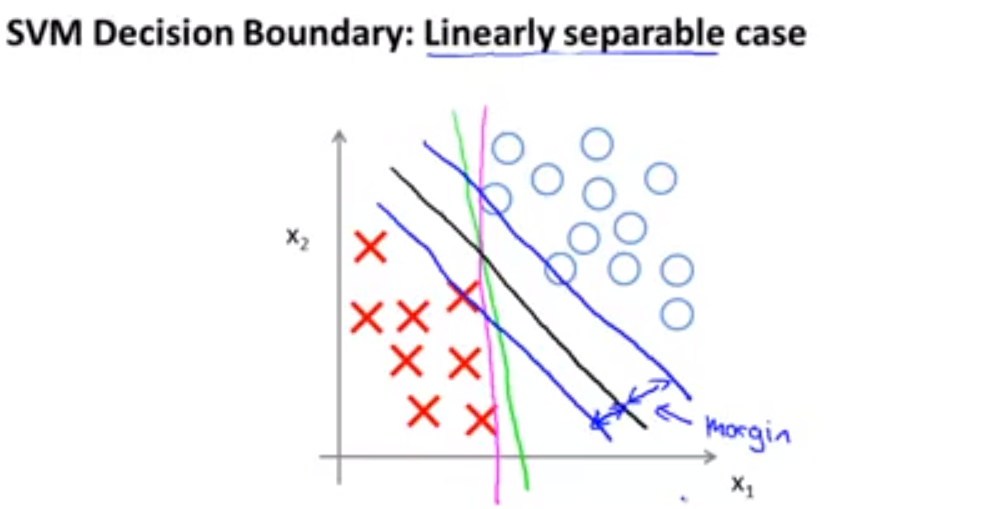
You can also check from the following image that how support vector machine will take care while making decision boundry in hypothesis function[ black line is the decision boundry by svm].So from the image we can see that it will also maintain large margin from both side.So SVM is also called large margin classifier.
Kernels In SVM
Now in order to develop complex nonlinear classifiers we will start adapting the support vector machine.The technique that we are going to use for doing this is called kernels.
More About SVM
Main work of SVM algorithm is to find a separating line[more generally which is called-hyperplane between data of two classes].So SVM algorithm will take our data as classes as input[in graph] and will return a best line that will separate that two classes in graph.
SVM will select a line that will maximize the distance to the nearest in either class and that distance is often called margin.For example in the following case SVM will pick the second line[the middle one] as a separator line:
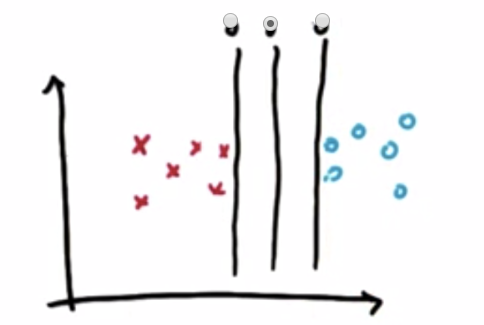
So remember two rules SVM will use to give us a separator line: SVM will first put and foremost correct classification of the labels and then after this only it will maximizes the margin.
SVM response to outliers
Suppose we have following two classes.So what will SVM do?
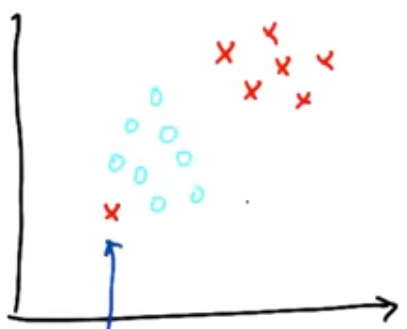
Even in this case also it will make same decision boundry in between them by tolerating[or ignoring] the outlier shown.So we can say that SVM is somehow robust to outliers.
Practical SVM in sklearn
Now we will head over to the coding part of SVM in which we take help of sklearn python module.So first you can go to this page to look at some basics of how to import SVM from sklearn: http://scikit-learn.org/stable/modules/svm.html
For example here is sample code:
import sys
from time import time
sys.path.append("../tools/")
from email_preprocess import preprocess
features_train, features_test, labels_train, labels_test = preprocess()
from sklearn.svm import SVC
clf = SVC(kernel="linear")
clf.fit( features_train, lables_train )
pred = clf.predict( features_test )
from sklearn.metrics import accuracy_score
acc = accuracy_score(pred, labels_test)
After importing SVC from svm we are creating classifier.After creating classifier we are fitting the data by calling the fit function.We are also predicting the accuracy by calling accuracy_score.
This is all about algorithm called support vector machine which are more powerful and better then many ml algorithms in certain situations.